Link: https://arxiv.org/pdf/2410.16707v1
Introduction or Motivation
- Inspiration
- will the performance imbalance at the beginning layer of the transformer decoder constrain the upper bound of the final performance?
- for this, conduct experiments to validate the negative impact of detection-segmentation imbalance issue on the model performance
- Core Idea: improve the final performance by alleviating the detection-segmentation imbalance.
- De-Imbalance (DI):
- generate balance-aware query
- Balance-Aware Tokens Optimization (BATO):
- guide the optimization of the initial feature tokens via the balance-aware query
- De-Imbalance (DI):

- Multi-Task Training Impact
- Multi-task training can sometimes degrade the performance of individual tasks.
- Crux of the Issue
- Imbalance Between Object Detection and Instance Segmentation
- A key factor is the imbalance between object detection and instance segmentation tasks.
- Imbalance Between Object Detection and Instance Segmentation
- Observed Phenomenon
- A performance imbalance exists between object detection and instance segmentation.
- Detection-Segmentation Imbalance
- The imbalance at the initial layers hinders the effective cooperation between object detection and instance segmentation.
- Reasons for Imbalance
- Individual Characteristics of Tasks
- Segmentation
- Nature: Pixel-level grouping and classification.
- Focus: Local detailed information is crucial.
- Detection
- Nature: Region-level task involving localization and regression of object bounding boxes.
- Focus: Requires global information, emphasizing the complete object.
- Segmentation
- Supervision Methods
- Segmentation Supervision
- Method: Densely supervised using all pixels of the ground truth (GT) mask.
- Impact: Provides richer and stronger information during optimization.
- Detection Supervision
- Method: Sparsely supervised using a 4D vector (x, y, w, h) of the GT bounding box.
- Impact: Less information compared to dense supervision.
- Segmentation Supervision
- Optimization Dynamics
- The dense supervision in segmentation leads to faster optimization compared to the sparse supervision in detection.
- This asynchronous optimization speeds contribute to the overall imbalance issue.
- Individual Characteristics of Tasks
Method
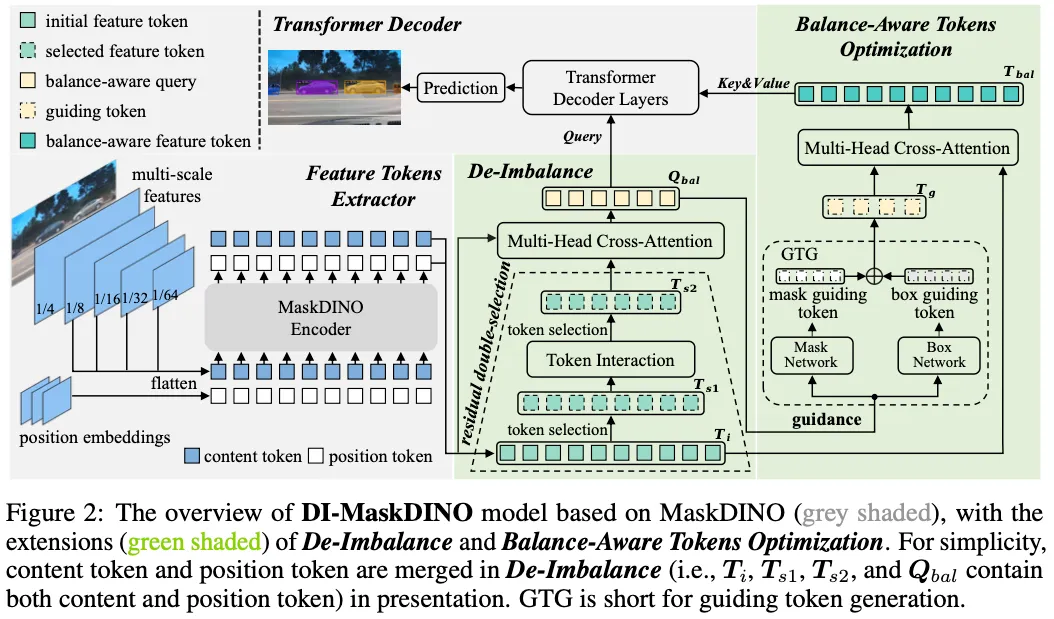
Feature Token Extractor
- Conventional DETR-like Encoder
De-Imbalance
- alleviate the imbalance instead of directly providing $T_i$ to the transformer decoder as MaskDINO does.
- detection-segmentation imbalance:
- the performance of object detection lags behind that of instance segmentation at the beginning layer of the transformer decoder.
- residual double-selection:
- select Top-$k_1$ ranked feature tokens in $T_i$ based on their category classification scores:
- $T_{s1}=\mathcal{S}(T_i,k_1)$
- most background information is filtered out, focusing on the objects
- The token interaction
- $T_{s1}^{sa}=\text{MHSA}(T_{s1})$
- the detection task to learn the interaction relation between patches.
- different tokens representing the patches (belonging to the same object) can interact with each other to learn
- benefiting the perception of object bounding boxes.
- the global geometric, contextual, and semantic patch-to-patch relations
- Second selection:
- $T_{s2}=\mathcal{S}(T_{s1}^{sa},k_2)$
- the residual is the necessary compensation for double-selection since the information loss occurs in the selection procedures
- $\mathcal{Q}{bal}=\text{MHCA}(T{s2}, T_i)$
- select Top-$k_1$ ranked feature tokens in $T_i$ based on their category classification scores:
Balance-Aware Tokens Optimization
- How $\mathcal{Q}_{bal}$ can guide the optimization of $T_i$?
- $T_i$ contains a large number of tokens conveying detailed local information for both background and foreground
- $\mathcal{Q}_{bal}$ consists of a small number of high-confidence tokens mainly focusing on foregrounds.
- Also, $\mathcal{Q}_{bal}$ has learned rich semantic and contextual interaction relation
- Therefore, $\mathcal{Q}_{bal}$ can guide the optimization of $T_i$
- Generate the guiding mask tokens
- $T_g^{mask}=\mathcal{N}{mask}(\mathcal{Q}{bal})$, $T_g^{box}=\mathcal{N}{box}(\mathcal{Q}{bal})$
- $\mathcal{N}(\cdot)$: MLP로 구성
- $T_g=T_{g}^{mask}+T_g^{mask}$
- $T_g^{mask}=\mathcal{N}{mask}(\mathcal{Q}{bal})$, $T_g^{box}=\mathcal{N}{box}(\mathcal{Q}{bal})$
- interacts $T_i$ and $T_g$
- the tokens $T_i$ that belong to the same object/instance will be aggregated, enhancing the foreground information.
- $T_{bal}=\text{MHCA}(T_{i}, T_g)$
Transformer Decoder
- $\mathcal{Q}{ref}=\mathcal{N}{decoder}(\mathcal{Q}{bal}, T{bal})$
- $\{c,b\}=\mathcal{N}{det}(\mathcal{Q}{ref})$
- $m=\mathcal{N}{seg}(\mathcal{Q}{ref}, T_i, F_{cnn})$
Experiment

