Link: https://arxiv.org/abs/2402.10093
Summary
A modified nearest neighbor objective constructs semantic clusters that capture semantic information which improves performance on downstream tasks, including off-the-shelf and fine-tuning settings.
Introduction or Motivation
For larger models, the light-weight decoder reaches a point, where it cannot further improve the pre-training objective on its own and passes part of the reconstruction task back to the last encoder blocks.
Consequently, the feature quality for downstream tasks of the later blocks degrades, and, somewhat unusual, the representation quality peaks in the middle blocks of the encoder.
Introduce MIM-Refiner:
- a sequential approach to refine the representation of a pre-trained MIM model to form semantic clusters via an ID objective
Introduce Nearest Neighbor Alignment(NNA):

- an ID objective that aligns each sample with its nearest neighbor while repelling other samples in a batch.
- Encoder vs Decoder: Encoder의 param이 대부분이다
- ViT Blocks의 feature로 k-NN했을 때 last block의 성능이 제일 좋진 않다
- last block’s representation quality가 떨어지면 down stream task의 성능도 안좋다.
- block간의 성능 차이를 구하고, max값으로 나눠 norm한 graph
- 중간 block의 경우 k-NN accuracy는 증가했지만 reconstruction loss는 거의 유지.
Authors observation
As models increase in size, the decoder eventually reaches a point where it cannot further improve the pre-training objective on its own.
Consequently, it begins to delegate a portion of the reconstruction task back to the last encoder blocks.
→ 모델이 커질 수록 decoder의 성능 한계로 인해 encoder로 reconstruction task의 책임(부담)이 생긴다. 이는 Fig. 3.의 1-shot ~ 5-shot과 같이 label이 적을 수록 큰 영향을 보인다.
Roughly speaking, the blocks of the encoder operate in three different regimes:
- Early: general purpose features are learned
- which improve the reconstruction loss and the k-NN accuracy simultaneously.
- Middle: abstractions are formed
- The reconstruction loss improves only slightly, while the k-NN accuracy improves drastically.
- Late: features are prepared for the reconstruction task
- The reconstruction loss improves at a faster rate, while the k-NN accuracy decreases.
결론적으로,
- When naïvely using the features of the last encoder block, those features are suited for reconstruction but not particularly for downstream tasks.
- fine-tuning 단계에서 데이터가 많으면 이런 문제가 완화 되겠지만, label이 적은 경우 downstream performance는 떨어질거다.
Method
Propose Nearest Neighbor Alignment(NNA):
- NN contrastive objectives introduce an inter-sample correlation by retrieving NNs of samples in a batch and subsequently applying an objective between the samples and their NNs.
Argument
the NN-swap does not offer a benefit for negative samples, since they are already different images, and instead, degrades the signal from the contrastive objective.
→ Negative sample에 대해서 NN-swap은 도움이 되지 않고 오히려 성능 저하를 야기한다.
그래서 Positive Sample에 대해서만 NN-swap을 수행하겠다.
$$ L^{\text{NNA}}i = - \log \frac{\exp(\text{NN}(z_i, Q) \cdot z_i / \tau)}{\exp(\text{NN}(z_i, Q) \cdot z_i / \tau) + \sum{j=1}^{N} \exp(\text{SG}(z_j) \cdot z_i / \tau) [i \neq j]} $$
$$ \text{NN}(z_i, Q) = \arg \max_{q \in Q} (z_i \cdot q) $$
- $z_i$: anchor
- $\text{NN}(z_i,Q)$: positive
- $z_j$: negatives
Experiment



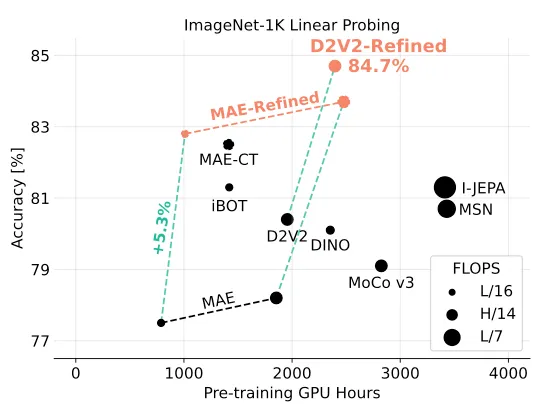
- Fewshot, linear probing, k-NN의 경우 제안한 refiner를 썼을 때 아주 큰 폭으로 성능 향상 → Representation이 좋아졌다.
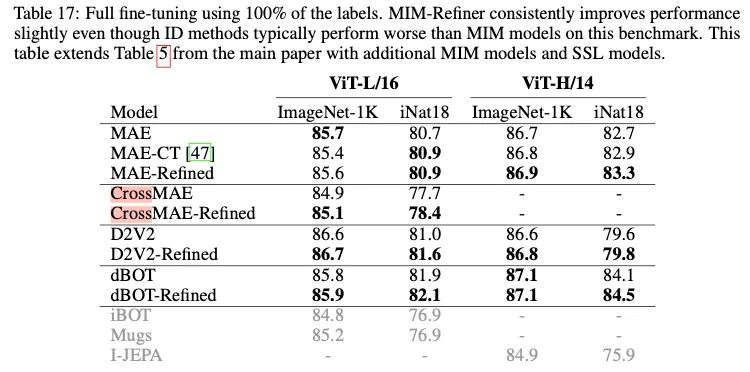
- 하지만 Full Fine-tuning(Fig. 17.)의 경우 성능 향상의 폭이 크지 않다.
- 위 그림에서 보면 pre-training gpu hours가 1.3배 정도 차이가 나기 때문에 full fine-tuning하는 경우 비용 측면에서 고민이 있어야 되겠다.