Link: https://arxiv.org/pdf/2409.13637
- 어떤 문제를 분석하고 문제를 해결했다기 보다는 기존 context text를 decoupling해서 text를 조금 더 다양하게 활용하자는 취지로써 여러 모듈을 제안
Introduction or Motivation
The one of key challenges for this RRSIS task is to learn discriminative multi-modal features via text-image alignment.
limitation of previous approach

- Linguistic representation is directly fused with the visual features by leveraging pixel-level attention.
- This is a concise and direct method, but it neglects the intrinsic information within the referring expression and the fine-grained relationship between the image and the textual description.
the original referring sentence is regarded as a context expression. It then is parsed into ground object and spatial position.
Propose:
- Fine-grained Image-text Alignment Module:
- simultaneously leverage the features of the input image and the corresponding text, better discriminative representations across modalities
- Text-aware Multi-scale Enhancement Module:
- adaptively perform cross-scale fusion and intersections under text guidance.
Method
Decompose the context into two fragments about ground objects and spatial positions(Fig.1.)
- $F_C$: original context text feature
- $F_G$: ground objects text feature
- $F_S$: Spatial position text feature
Fine-Grained Image-Text Alignment

- Object-Position Alignment Block(OPAB):
- perform the intersection of features of ground object and spatial position with the visual representation
- Ground Object Branch:
- multi-fusion between the textual features of ground objects and the visual features
- enhance the discriminative ability of the model on the referent target
- Spatial Position Branch:
- capture the spatial prior guided by the original visual feature and textual features of positional description
- better integrated with the ground object features
- Context Alignment with Visual Features:
- Original context text가 context 정보를 더 많이 가지고 있을 거라서 image feature랑 Pixel-Word Attention하겠다.
- Pixel-Word Attention Module을 통해서 구현.
- Channel Modulation:
- Readjust the extracted multi-modal features which can further enhance the discriminative ability of the proposed method
Text-Aware Multi-Scale Enhancement

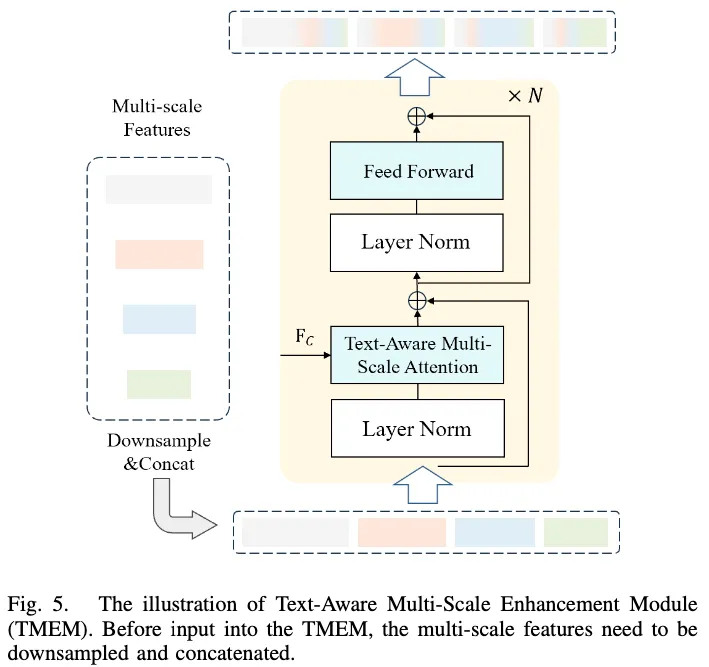
- 모든 image feature를 last image feature space에 맞춰 downsampling을 한다.
- 그 다음 모든 image feature를 concatenate해서 text feature와 ‘text-aware multi-scale attention’을 수행한다.
- 이 때 사용되는 text feature는 context text feature $F_C$다.
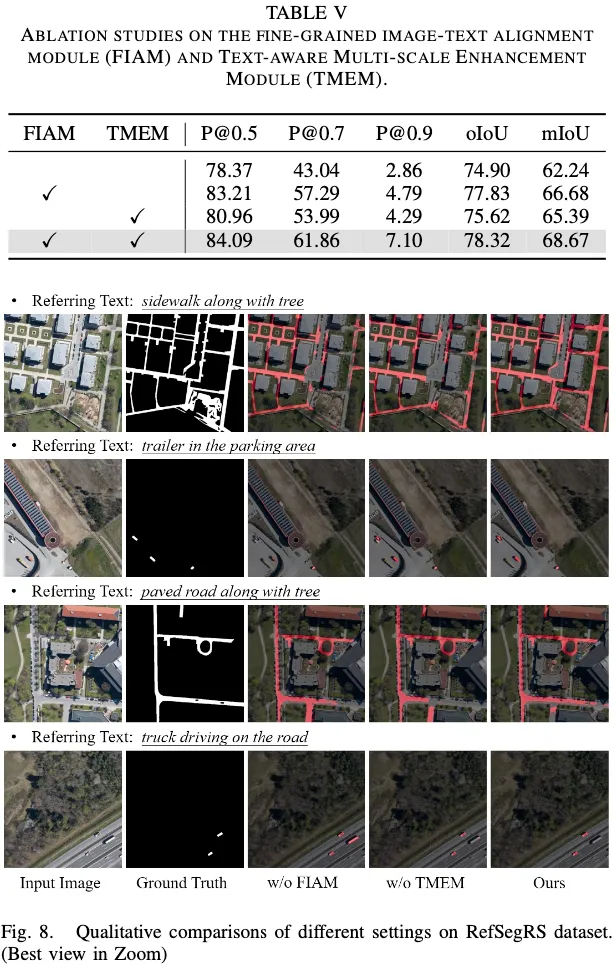
Experiment
- Model: Swin from ImageNet-22K+ BERT
- Dataset:
- RefSegRS: 60e, 5e-5 lr
- RRSIS-D: 40e, 3e-5 lr
- weight decay: 0.1
- HW: a 4080 with bs 8