ECCV 2024 Accepted Paper
- SimCLR등과 같은 방법론에서 제안하는 multi-modal contrastive learning을 사용
Summary
- Satellite Metadata-Image Pretraining (SatMIP)
- A new approach for harnessing metadata in the pretraining phase through a flexible and unified multimodal learning objective.
- Represents metadata as textual captions and aligns images with metadata in a shared embedding space by solving a meta data image contrastive task.
- SatMIPS
- combining image self-supervision and metadata supervision
- Improves over its image-image pretraining baseline, SimCLR, and accelerates convergence.
Encodes pairs of images and metadata as separate modalities and aligns them in a deep embedding space via a contrastive task
Introduction or Motivation
- Within satellite imagery, metadata such as time and location often hold significant semantic information that improves scene understanding.
- we aim to learn a visual encoder that embeds metadata information, and their latent se- mantic characteristics, into image features.
- By co-solving an image-image and a metadata-image contrastive task with an efficient “coupled” architecture, SatMIPS benefits from both sources of supervision, and improves over it’s SimCLR baseline, yielding better representations while converging faster.
Method

SatMIP
- Contrastive Loss
- $\mathcal{L}^{\text{clr}}(a_i, b_i) = - \log \left( \frac{\exp(s(a_i, b_i)/\tau)}{\sum_{j=1}^{K} \exp(s(a_i, b_j)/\tau)} \right)$
- $\mathcal{L}_{i}^{\text{MI}}(\mathbf{z}_i^{\mathcal{I}}, \mathbf{z}_i^{\mathcal{M}}) = \frac{1}{2} \left( \mathcal{L}^{\text{clr}}(\mathbf{z}_i^{\mathcal{I}}, \mathbf{z}_i^{\mathcal{M}}) + \mathcal{L}^{\text{clr}}(\mathbf{z}_i^{\mathcal{M}}, \mathbf{z}_i^{\mathcal{I}}) \right)$
- $z^{\mathcal{I}}$: Image embedding feature
- $z^{\mathcal{M}}$: Meta embedding feature
- Note that there does not exist a simple 1:1 mapping between images and metadata, because metadata can match many image variations and vice versa
- e.g., due to the non-deterministic nature of weather.
- This prevents the model from solely overfitting the pretext task. In addition, we apply data augmentation to the images which further regularizes the task.
SatMIPS
- SimCLR like Contrastive loss: image-image & image-meta
- $\mathcal{L}_{i}^{\text{Sim}}(\mathbf{z}_i, \mathbf{z}_i') = \frac{1}{2} \left( \mathcal{L}^{\text{clr}}(\mathbf{z}_i, \mathbf{z}_i') + \mathcal{L}^{\text{clr}}(\mathbf{z}_i', \mathbf{z}_i) \right)$
- $\mathcal{L}_{i}^{\text{MI+Sim}}(\mathbf{z}_i^{\mathcal{I}}, \mathbf{z}_i^{\mathcal{M}}, \mathbf{z}i, \mathbf{z}i') = \mathcal{L}{i}^{\text{MI}} + \lambda \mathcal{L}{i}^{\text{Sim}}$
- $\lambda$: set 1 as default
Experiment
Dataset
- fMoW-RGB로 pretraining
- The metadata is composed of a diverse set of metadata fields
- GSD, timestamp, location, location-derived information such as UTM zone and country, cloud cover, and various imaging angles
- 1024 global batch
- 1 epoch of linear warmup


- Encoders:
- Visual Encoder: ViT-S/16 from MoCo V3
- Meta Encoder:
- Textual metadata encoder:
- BERT-style Transformer encoder with 3 layers, width 512, 8 attn head, ffn factor of 4
- Tabular metadata encoder
- convert it into atomic numerical or categorical field
- FT-Transformer with 3 layers, width 192, 8 attn head, ffn factor of 4/3
- Textual metadata encoder:
Experimental Results
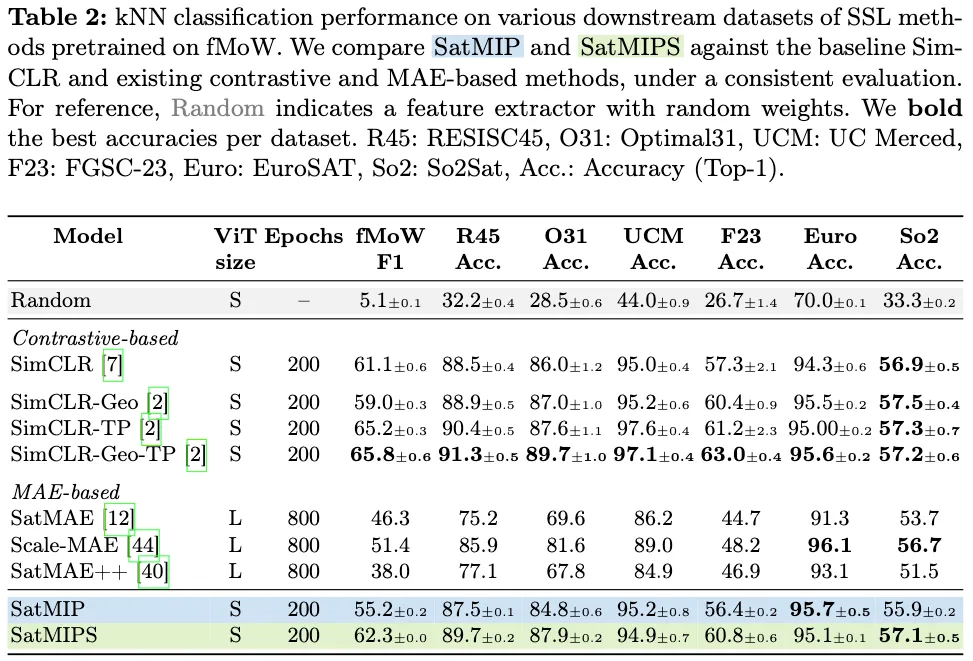


- Location을 Meta 정보로 활용했을 때 다른 것들에 비해서 성능 향상 폭이 크다.
