Summary
- Introduce ImageRAG for RS, a training-free framework to address the complexities of analyzing UHR remote sensing imagery.
- The high spatial resolution results in massive image sizes (e.g. 100, 000 × 100,000 pixels), making it difficult to directly train neural networks with such images due to the limitation in GPU memory.
Introduction or Motivation
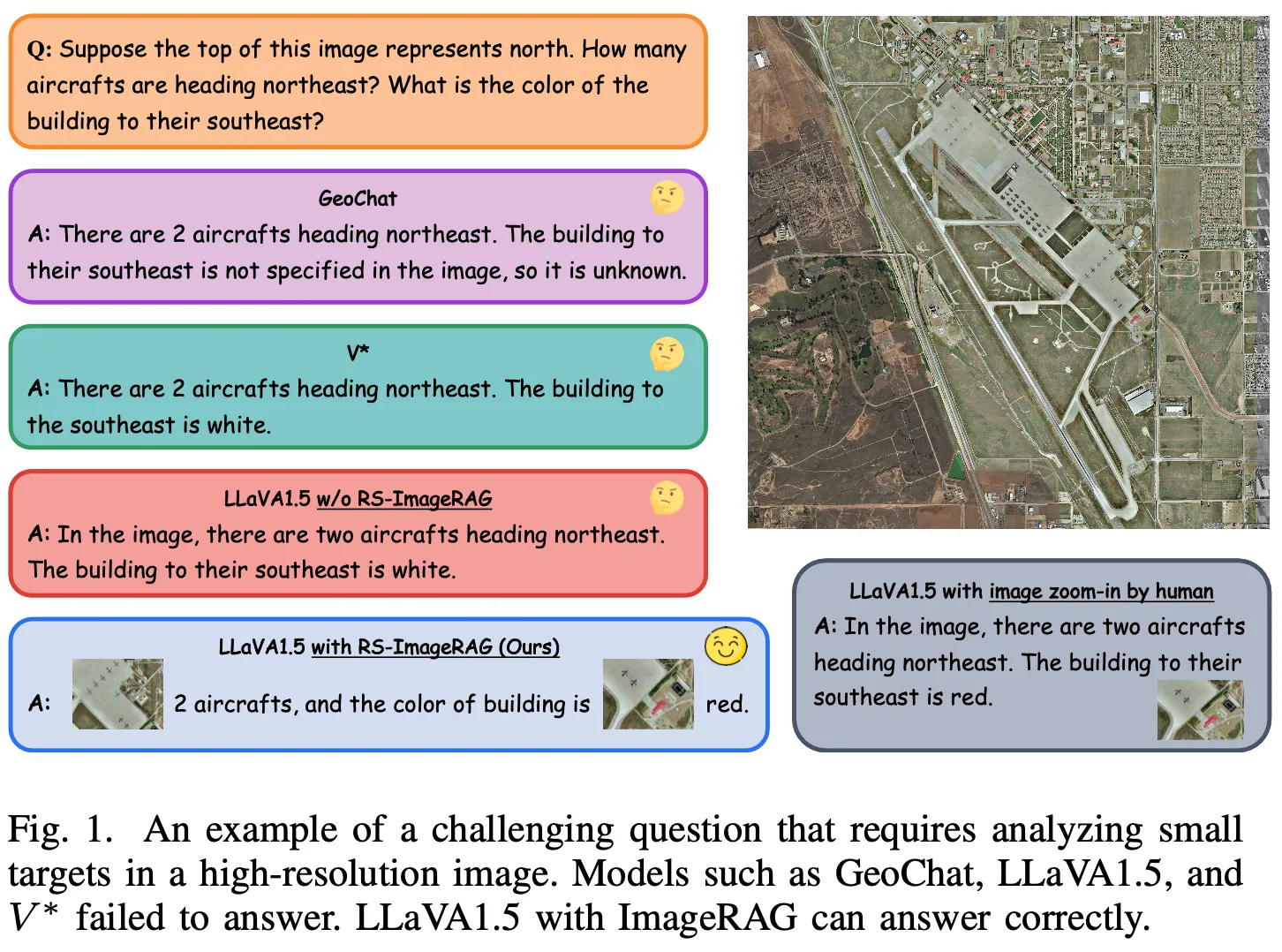
- The model’s limitations in handling fine details and distinguishing small features become evident, leading to inaccurate responses when tasked with analyzing such intricate visual information
- four types of approaches for applying MLLMs to UHR RSI
- resizing UHR images to a smaller size:
- Cons: this significantly reduces the visibility of small objects in the images
- divides UHR images into smaller patches that can be sequentially processed by MLLMs:
- results in the loss of global and relative information and relationships present in the original large-scale image
- references techniques from general LLMs for managing long context
- Ex) Positional Interpolation and LongROPE
- potentially enable the integration of entire UHR images while maintaining global information.
- it would necessitate retraining the models from scratch
- employs guided visual search methods that focus on relevant patches
- Ex) V* or LongLLaVA
- requires retraining the model and demands task-specific annotations
- resizing UHR images to a smaller size:
- Three crucial aspects for MLLMs to effectively handle UHR RSI
- managing small targets
- processing the UHR image in a way that integrates with MLLMs without significantly increasing the number of image tokens
- achieving these goals while minimizing the need for additional training or specialized annotation.
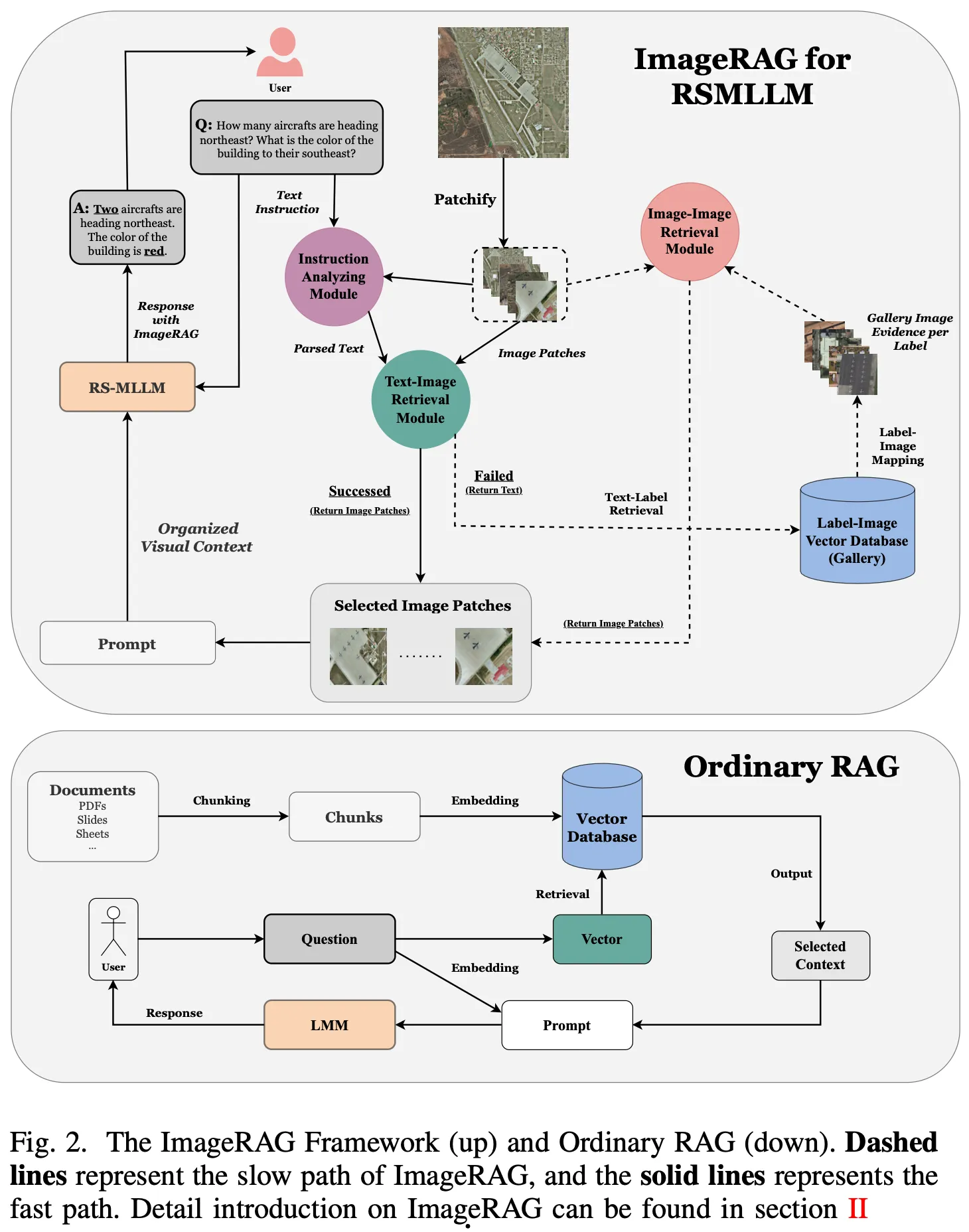
ImageRAG
- retrieves and emphasizes relevant visual context from the UHR image based on the text query
- focus on important details, even tiny one.
- integrates various external knowledge sources to guide the model
- enhancing the understanding of the query and the UHR RSI.
- training-free
Method
Retrieval
- Given an image: $I_i$
- a text query: $T_i$
- a Patch Division Approach: $F$
- an Instruction Analyzing Module: $G$
- a Text-Image Retrieval Module: $M_{ti}$
- including image encoder $f_{\text{img}}$
- text encoder:$f_{\text{text}}$
- select function $H_{\text{fast}}$ with threshold $\epsilon$
- a Label-Image Vector Database $D$ with threshold $\delta$
- an Image-Image Retrieval Module $M_{ii}$
- including image encoder $f_{\text{img}}$
- text encoder \( f_{\text{text}} \)
- select function: $H_{\text{slow}}~\text{with threshold} (\epsilon)$
- The visual context \( V_i \) can be selected by:
- $V_i = \begin{cases} M_{ti} (I_i, T_i \mid (F, G, f_{\text{img}}, f_{\text{text}}, H_{\text{fast}})) & \text{for fast path} \\ M_{ii} (I_i, T_i, D \mid (F, G, f_{\text{img}}, f_{\text{text}}, H_{\text{slow}})) & \text{for slow path} \end{cases}$
1) Image Patch Division Approach
- Set of image patches: $P_i=F(I_i)=\{p_i^j\}^m_{j=1}$
2) Instruction Analyzing Module
- Set of key phrases $Q_i=G(P_i, T_i)=\{t_i^j\}^n_{j=1}$
3) Text-Image Retrieval Module:
- $S_{\text{fast}}=f_{\text{text}}(Q_i)\odot f_{\text{img}}(P_i)^{T}$
- Visual context $V_i = H_{\text{fast}}(P_i, S_{\text{fast}}, \epsilon)=\{v_i^j\}^k_{j=1}$
- 만약 여기서 k가 0이라면 더욱 복잡한 slow path를 실행한다.
4) Label-Image Vector Database (Gallery): Slow path
- the Label-Image Vector Database D
- stores million-scale labeled RSI with the key-value pairs
- the key:
- text embedding of the class name
- generated using the text encoder $f_{\text{test}}$
- the value:
- mean of the image embedding
- obtained using the image encoder $f_{\text{img}}$ with the set of images associated with that class.
- Given a set of query key phrases $Q_i = \{ t_i^j \}_{j=1}^n$, the database $D$ retrieves corresponding labels $L_i = \{ l_i^p \}$.
- These labels $L_i$ are selected based on high semantic similarity with the query embeddings $f_{\text{text}}(Q_i)$
- Retrieval process can be expressed as:
- $L_i = \{ l_i^p \} = D(f_{\text{text}}(Q_i), \delta)$
- $l_i^p$: a label in the database related to the query $Q_i$, where $\delta$ is the similarity threshold.
- The mean image embeddings associated with the retrieved labels $L_i = \{ l_i^p \}$ are provided as $E_i = \{ e_i^p \}$.
- $E_i$ forms the set of relevant visual concepts within $D$ for the given queries $Q_i$.
- Fast path failure suggests that no visual concept has been confidently identified for the key phrases.
- This general training makes it difficult for the VLM to associate RS-specific visual concepts with text descriptions.
- To resolve this, the slow path uses text embeddings of phrases and labels as anchors, retrieving image embeddings from the RS database for these concepts.
- Retrieved image embeddings serve as visual evidence for later image-to-image searches, enhancing the model's RS domain-specific concept understanding.
5) Image-Image Retrieval Module:
- Visual evidence $E_i = \{ e_i^p \}$ for each label is obtained.
- Similarity matrix $S_{\text{slow}}$ between patches $P_i$ and visual evidence $E_i$ is calculated as:
- $S_{\text{slow}} = E_i \otimes f_{\text{img}}(P_i)^\top$
- Visual context $V_i$ for the slow path is selected based on $S_{\text{slow}}$ and threshold $\epsilon$ using selection function $H_{\text{slow}}$
Generation Stage
- Objective: Utilize selected visual contexts $V_i$ from image patches $P_i$ of image $I_i$ for response generation.
- Difference from Ordinary RAG:
- Ordinary RAG: Organizes retrieved text content with a prompt and sends it to an LLM for response generation.
- ImageRAG: Must handle both visual and textual contexts, requiring a model that can process visual cues effectively.
- Solution:
- Model Selection: ImageRAG selects a Multimodal Language Model (MLLM) capable of using visual contexts.
- Chosen Model: VQA (Visual Question Answering) LLM from the $V^*$ framework, specifically designed to handle additional visual information.
- Prompt Design: A carefully crafted prompt is used to guide the model, enhancing its focus on relevant visual contexts.
- Calculation of Response \( R_i \):
- For a given image $I_i$ and text query $T_i$:
- $R_i = \text{VQALLM}(I_i, V_i, T_i \mid \text{Prompt})$
- For a given image $I_i$ and text query $T_i$:
Experiment
어…. 이렇다 할게 없습니다…
'AI' 카테고리의 다른 글
| Relation DETR: Exploring Explicit Position Relation Prior for Object Detection (0) | 2024.12.09 |
|---|---|
| FS-DETR: Few-Shot Detection Transformer with prompting and without re-training (0) | 2024.11.17 |
| Scattering Vision Transformer: Spectral Mixing Matters (0) | 2024.11.06 |
| SpectFormer: Frequency and Attention is what you need in a Vision Transformer (0) | 2024.11.06 |
| Inception Transformer (0) | 2024.11.06 |
